事先声明,这篇文章的标题绝不是在耸人听闻。事情的起因是今天早上在朋友圈看到同学在转发一篇论文,名字叫《Create Anime Characters with A.I. !》网站的地址为:MakeGirls.moe。
下图左侧为通过属性blonde hair, twin tails, blush, smile, ribbon, red eyes生成的人物,右侧是通过属性silver hair, long hair, blush, smile, open mouth, blue eyes生成的人物,都表现得非常自然,完全看不出是机器自动生成的:
模型生成的随机样本:
固定cGAN噪声部分生成的样本,此时人物具有不同的属性,但是面部细节和面朝的角度基本一致:
更加令人兴奋的是,作者搭建了一个网站,任何人都能随时利用训练好的模型生成图像,进行实验!网站的地址为:MakeGirls.moe。
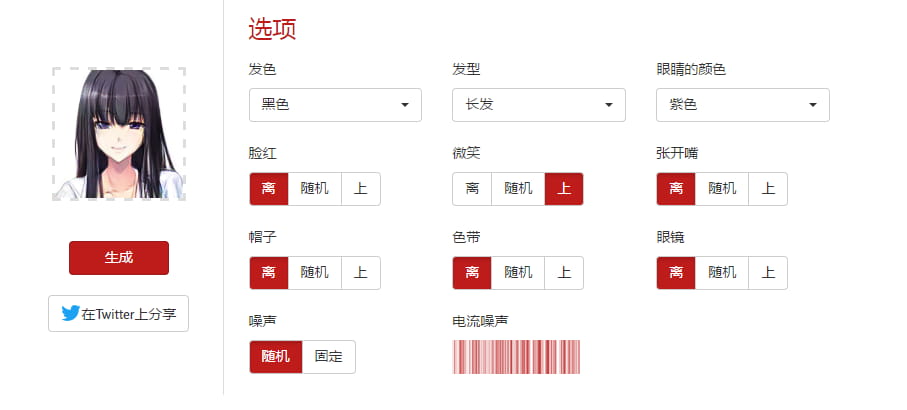 这是小编自己生成的黑长直,感觉还可以
这是小编自己生成的黑长直,感觉还可以
打开网站后需要等待进度条加载完毕,这个时候是在下载模型:
这里的按钮的含义都比较简单,总的来说我们要先选定一些属性(完全随机也是可以的),然后点击左侧的generate按钮生成:
技术细节
我之前也写过两篇文章,一篇介绍了GAN的原理(GAN学习指南:从原理入门到制作生成Demo),一篇介绍了cGAN的原理(通过文字描述来生成二次元妹子!聊聊conditional GAN与txt2img模型),这两篇文章都是以生成 二次元人物来举例,但是生成的结果都比较差,只能看出大概的雏形。今天的这篇论文大的技术框架还是cGAN,只是对原来的生成过程做了两方面的改进,一是使用更加干净、质量更高的数据库,二是GAN结构的改进,下面就分别进行说明。
改进一:更高质量的图像库
之前使用的训练数据集大多数是使用爬虫从Danbooru或Safebooru这类网站爬下来的,这类网站的图片大多由用户自行上传,因此质量、画风参差不齐,同时还有不同的背景。这篇文章的数据来源于getchu,这本身是一个游戏网站,但是在网站上有大量的人物立绘,图像质量高,基本出于专业画师之手,同时背景统一:
除了图像外,为了训练cGAN,还需要图像的属性,如头发颜色、眼睛的颜色等。作者使用Illustration2Vec,一个预训练的CNN模型来产生这些标签。
改进二:GAN结构
此外,作者采取了和原始的GAN不同的结构和训练方法。总的训练框架来自于DRAGAN(arxiv:[https://arxiv.org/pdf/1705.07215.pdf)],经过实验发现这种训练方法收敛更快并且能产生更稳定的结果。
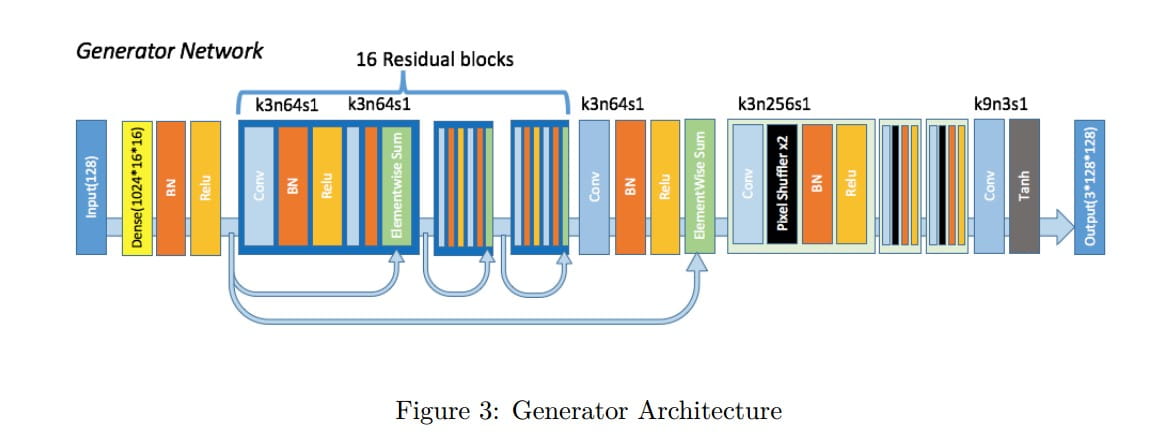
生成器G的结构类似于SRResNet(arxiv:[https://arxiv.org/pdf/1609.04802.pdf)]:
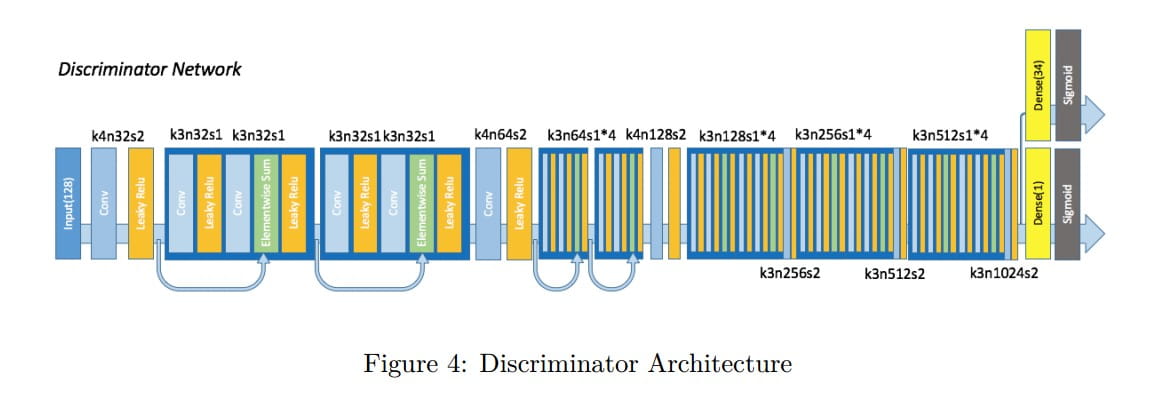
判别器也要做一点改动,因为人物的属性相当于是一种多分类问题,所以要把最后的Softmax改成多个Sigmoid:
详细的训练和参数设定可以参照原论文。
一些问题
虽然大多数的图像样本都比较好,但作者也提出了该模型的一些缺点。由于训练数据中各个属性的分布不均匀,通过某些罕见的属性组合生成出的图片会发生模式崩坏。比如属性帽子(hat)、眼镜(glasses),不仅比较复杂,而且在训练样本中比较少见,如果把这些属性组合到一起,生成的图片的质量就比较差。
如下图,左侧为aqua hair, long hair, drill hair, open mouth, glasses, aqua eyes对应的样本,右侧为orange hair, ponytail, hat, glasses, red eyes, orange eyes对应的样本,相比使用常见属性生成的图片,这些图片的质量略差:
总结
这项工作确实令人印象深刻,生成的图片质量非常之高,个人认为如果加以完善,完全可以在某种程度上替代掉插画师的一部分工作。最后附上文中提到的一些资源:
网站:MakeGirls.moe(已有训练好的模型,打开就可以尝试生成)
论文:[http://make.girls.moe/technical_report.pdf]
Github:make.girls.moe(目前只有网站的js源码,看介绍训练模型的代码会在近期放出)
http://bbs.ngacn.cc/read.php?&tid=12233130
 二次元资讯
二次元资讯
 慢慢说
慢慢说
 道听途说
道听途说
 展会资讯
展会资讯

 投稿专区
投稿专区







")







